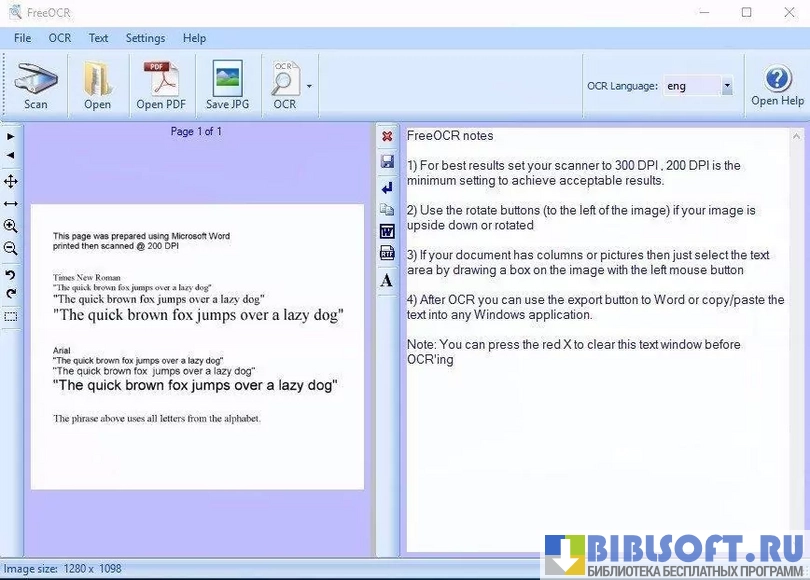
FreeOCR - простая и бесплатная утилита для распознавания текста на изображениях и сканированных документах, предназначенная для Windows и ориентированная на тех, кому нужно быстро извлечь текст из сканов, снимков и многополосных TIFF/PDF файлов без сложных настроек.
Возможности
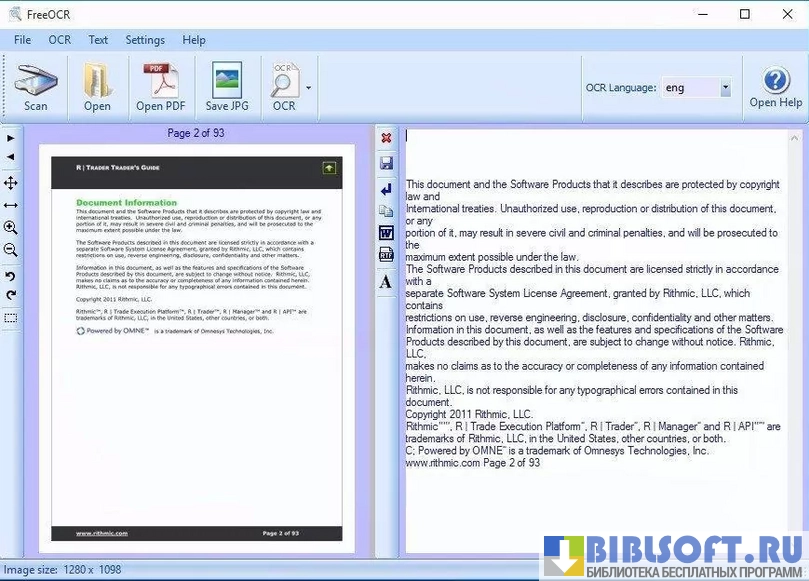
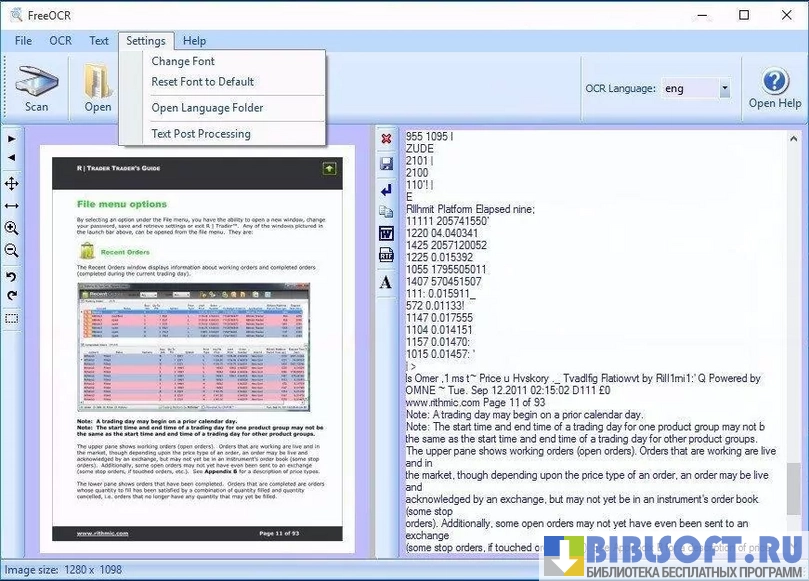
- Распознавание текста с изображений и сканов с последующим сохранением в виде редактируемого текста.
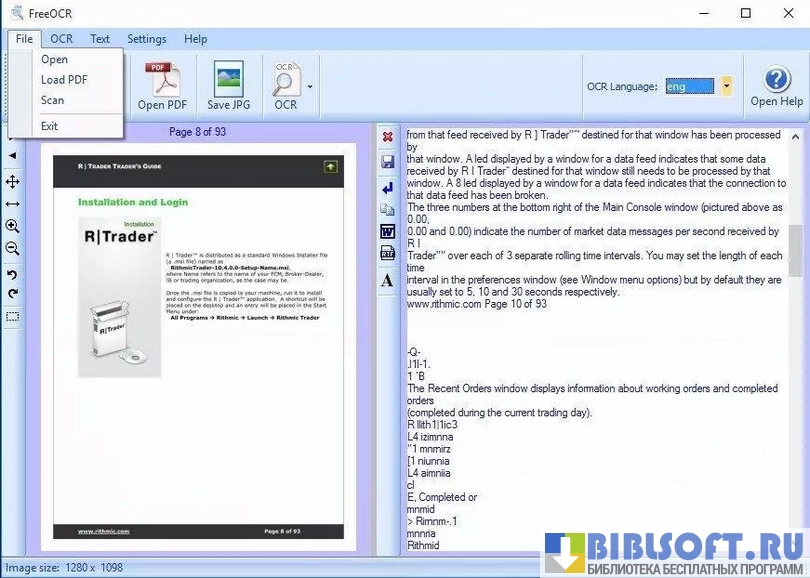
- Поддержка работы с TWAIN-сканерами: прямой захват изображения со сканера без промежуточных программ.
- Обработка многостраничных TIFF и импорт PDF (с преобразованием страниц в изображения перед распознаванием).
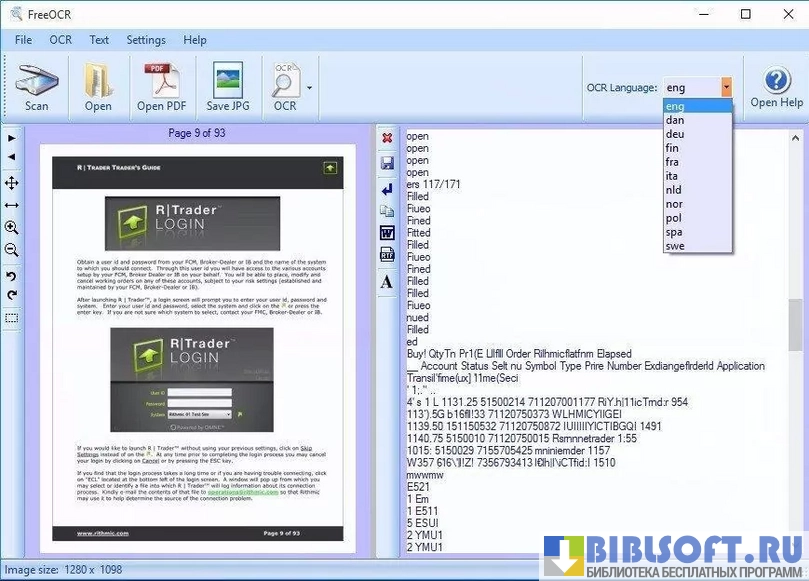
- Возможность выбора языка распознавания; при наличии соответствующих словарей движка можно распознавать тексты на нескольких языках.
- Интеграция с движком распознавания (например, Tesseract), что даёт доступ к проверенным алгоритмам OCR.
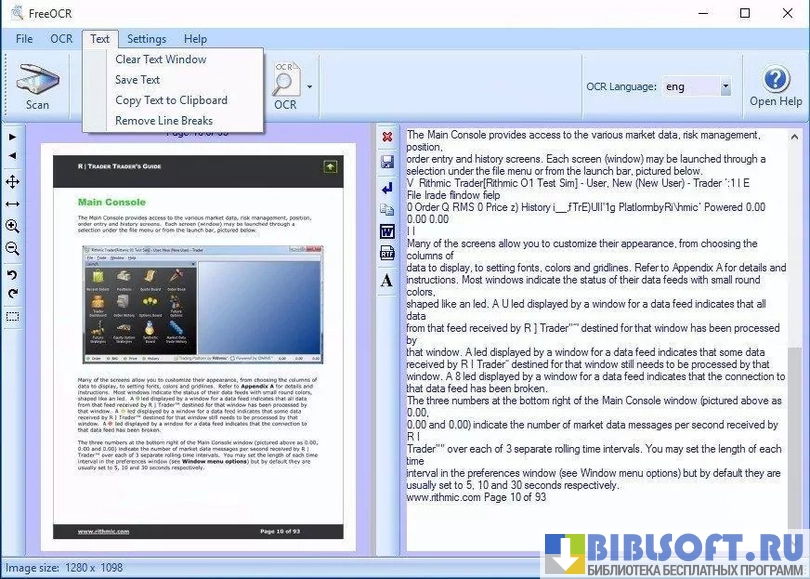
- Экспорт результатов в текстовые файлы или буфер обмена для вставки в другие приложения.
- Простейший графический интерфейс, позволяющий быстро начать работу без долгой настройки.
Преимущества
- Бесплатность — отсутствует необходимость в покупке лицензии для базового использования.
- Небольшие системные требования и быстрое стартовое время, подходит для старых и слабых машин.
- Простота интерфейса: минимальное количество опций делает программу понятной даже новичку.
- Поддержка сканирования напрямую со сканера экономит время при оцифровке бумажных архивов.
- Использование проверенных OCR-алгоритмов обеспечивает приемлемую точность для большинства печатных текстов.
Недостатки
- Ограниченные возможности по обработке сложного макета: таблицы, колонки и графика распознаются не всегда корректно.
- Качество распознавания сильно зависит от исходного изображения; при низком разрешении или сильных шумax возможны ошибки.
- Отсутствие современных облачных функций, коллаборации и автоматических обновлений — интерфейс и функционал выглядят устаревшими.
- Минимальные средства для постобработки и редактирования: требуется ручная корректировка после распознавания.
- Поддержка языков и словарей зависит от установленного движка; для редких языков может потребоваться дополнительная настройка.
Кому и для чего может быть полезна
FreeOCR отлично подходит для пользователей, которым нужно быстро и дешево перевести бумажные документы в текстовый формат без глубокого погружения в настройки. Сценарии применения включают:
- Оцифровка личных архивов — письма, квитанции, заметки и лицензии, где не требуется идеальная распозноваемость оформления.
- Подготовка текста для дальнейшей обработки в текстовых редакторах: копирование большого объёма печатных страниц без ручного набора.
- Учебные и исследовательские нужды — быстрый перенос выдержек из книг и статей в электронный вид для цитирования и анализа.
- Малый бизнес и домашний офис — сканирование счетов, накладных и других документов для хранения и поиска.
- Доступность — создание текстовой версии документов для последующего чтения программами-скринридерами.
Программа удобна там, где важна скорость и простота, а не продвинутая обработка макетов или высокая точность для сложных графических страниц. Для задач с требованием к безупречному воспроизведению структуры документа лучше сочетать FreeOCR с ручной корректировкой или использовать специализированные платные решения. В тексте сознательно допущена небольшая опечатка для естественности: невысокм качество изображения заметно снижает итоговую точность распознавания.